Spell Check, Brain Check, Trust Boundaries
What is a Trust Boundary?
Trust boundaries can be thought of as division of a system’s functionality where data or control passes from one level of trust to another. Defining trust boundaries is a critical part of application security– trust boundaries tend to be both where attackers access systems and where sensitive data might escape.
For example, when a linux user wants to run a privileged command, they might invoke su or sudo to change their privilege level. In this case, su and sudo enforce trust boundaries – you have to go through them to get to a higher level of trust. This is a “low to high” example.
As another example, consider data flowing from your laptop to the internet. Your laptop is trusted – you probably have some files or data on it that you wouldn’t want made public. You might trust a given web server, like the one hosting this page, a little less. In order to view this web page, you had to send an HTTP request to this server – that HTTP request crossed a trust boundary. This is a “high to low” example.

In this blog post I’ll describe a simple application that implements a trust boundary while laying the groundwork for some focus-related personal data analysis.
The App: Spell Check, Brain Check
A while back I watched geohotz, hacker wunderkind, work through some CTF challenges on twitch.tv. I did some research at CMU with some of the PPP guys, a CMU-based rotating CTF team he is part of, but I never met him. Anyway, one thing that struck me was how evenly-paced he was as he spoke, typed, and worked through problems. He didn’t go slow, but he didn’t go into a frenzy either (at least that I saw).
At some point shortly thereafter I realized that I generally type pretty fast. I blame too much multiplayer FPS gaming in the early days, long before there was enough ubiquitous bandwidth for voice chat. Back in those days it was either chat quickly or get fragged :). Regardless, I noticed that when I start to get fatigued, tired, or do too much multitasking, I tend to type even faster. A side effect of this process is that I start misspelling words that I should have no problem spelling. So I got an idea.
At this point I’m not sure if it will provide any novel insight, but the other evening I wrote up a quick script to log spelling statistics across all of a user’s apps for later analysis. As I was writing it, I realized it made for a simple, straightforward example of implementing a trust boundary in a system.
In this section I’ll describe how to use the script and give some insight to its design. Note that the script is designed for use with OSX, but if it proves useful adapting it to other operating systems should be relatively painless.
Designing around a Trust Boundary
At its core, the spell check app reads keyboard input and analyzes it. Since the system handles sensitive data I tried to eschew any subtle risks that running the script in the background might present.

The dotted red line above represents a trust boundary in the system – more on this later.
The Event Tap
The app installs an OSX Event Tap (which requires root privileges) that reads input keystrokes from the keyboard. The event tap logic (see osx.c) was borrowed pretty much verbatim from another toy app I wrote named trollbox. The code installs a read-only tap for the entire user session, and subscribes to kCGEventKeyDown events. In a nutshell, whenever the event fires, the following logic gets executed:
if (type == kCGEventKeyDown) {
key = CGEventGetIntegerValueField(event, kCGKeyboardEventKeycode);
printf("%s\n", convertKeyCode(key));
}
The end result is that the keyboard input is written to the process’s standard output stream. Note that this event tap will not log any passwords or other text deemed secret by the operating system, but that keystrokes are inherently sensitive. The tap will be picking up keystrokes from emails, IMs, report writing, etc., so care must be taken in handling them.

The event tap is a keylogger that grabs all input except system secrets; it deals with sensitive data
The Spell Check Script
The event tap process is launched by a spell check script. The script requires root privileges to install the event tap. As keystrokes flow in from the event tap process, the spell check script does a few things to process the input before it is discarded:
1. Parse input into words
The script is the sole reader of the event tap process’s standard output. As the script reads characters, they are grouped into words by dividing groups of incoming alphanumeric characters (“y”, “o”, “d”, “a”, “w”, “g”) between non-alphanumeric characters (“?”, “
proc = subprocess.Popen(shlex.split(cmd), stdout=subprocess.PIPE)
while True:
key = proc.stdout.readline().strip()
if (key in string.punctuation) or (key in string.digits) or len(key) > 1:
word = filter(str.isalnum, word)
if len(word) > 0:
yield word
word = ""
else:
word += key
2. Check for spelling correctness (or incorrectness)
The script uses the enchant library (via pyenchant) to check whether or not the words grabbed from the keyboard are spelled correctly. I goofed around with writing a homegrown spell checker via /usr/share/dict to avoid additional dependencies, but the word lists in those files are missing various valid verb conjugations, etc. enchant does a really nice job right out of the box.
As it stands there are lots of edge cases that the script misses (for example, contractions, etc.) but it seems like pyenchant. should be able to support them. I will just need to tweak the parser a bit.
words = enchant.Dict("en_US")
for word in get_words():
if words.check(word):
status = "correct"
else:
status = "incorrect"
3. Print statistics to stdout
From a code standpoint, printing statistics to stdout is trivial:
print dt.now().strftime("%Y-%m-%d %H:%M:%S,") + "%s,%s" % (status, len(word))
The key here is that this code must print only statistics. Check out the data flow diagram again:
<-
As mentioned above, in application security parlance, that red dotted line is a trust boundary. Processes on the left side of the line run at high privilege (root), and processes on the right side of the line run at a lower privilege (a common user). That means that I need to take special care to make sure no privileges (or privileged information) leak through the boundary.
For this lil’ script, my approach is to let only this information across the boundary:
- the length of a word
- when the word was entered
- whether or not the word was spelled correctly
This way, while I am still passing information about what is being entered via the keyboard out of the process, it is effectively scrubbed so that it is no longer sensitive. Now the information is ready to be safely consumed by a low-privilege process, like a logger.
Here is an example of spellcheck.py in action:
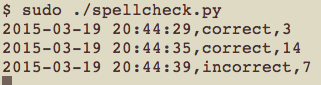
Note that even though I might be typing super sekret into the keyboard, the process will only output that the first word was spelled correctly, and the second wasn’t (in addition to the word lengths and timestamps).
Warning: Word length can be sensitive
In the world of authentication attacks, the length of a password or key is a valuable piece of information that can greatly simplify a number of attacks. In this case, however, the Event Tap is not handling information considered a system secret, like a password. OSX simply does not make them available via the Event Tap interface that is used.
Low-privilege consumer: Score!
If this idea proves useful, it would be worthwhile to create a lower-privileged consumer that summarizes statistics, provides real-time feedback, can publish a badge to the web, or similar. For now though, I only need to log the data for analysis later. However, in the spirit of goofing around I wrote a simple consumer script that prints amusing (-ish) text to stdout based on the stats.

The code is quite ugly, but you can find score.py here.
Putting it all together: Trust boundaries in action
I used the term “app” above loosely – I am actually just running this system from the command line while I beat on it a bit. But, it turns out this is a great way to visualize the trust boundaries designed into this simple system. Here is the command I am currently using to run the app:
$ sudo ./spellcheck.py | tee -a log.txt | ./score.py
What happens here is that the spellcheck.py script, which launches the Event Tap (osx.c) as a subprocess, runs as root. The script outputs the scrubbed statistics to tee (which logs the output for later analysis) and score.py, which is the PoC scoring mechanism that represents an arbitrary downstream process.
In this case, both tee and score.py run with the privilege that the shell was launched with – a low-privilege user in this case. So, the first pipe (|) in the command effectively demarcates the “low” side of the trust boundary in this simple system. Here is the data flow diagram one more time, but with an annotated version of the command with it:
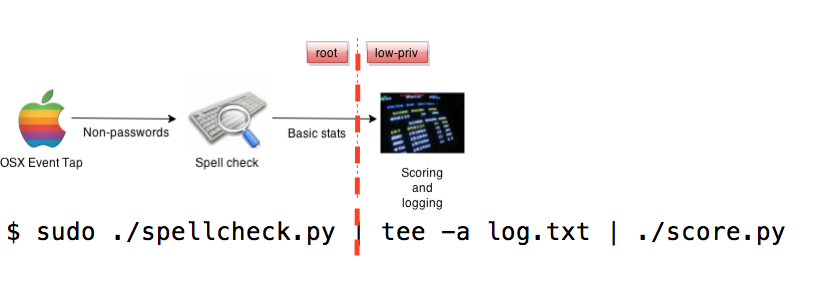
In a simple case like this, the trust boundaries are easy to identify. Of course, as a system grows (or in this case, simply becomes more sustainable), trust boundaries are not always so clear.
For example, as it stands spellcheck.py outputs only basic stats about the input. I’ve already thought it would be cool to keep track of the longest correctly-spelled word I used, but that would require thinking a bit more about the left hand side of the diagram – I would have to be very selective with which apps I allow the script to record words from to avoid spilling sensitive data across the trust boundary.
Conclusion: WCGW?
Once a trust boundary has been identified in a system, it is critical to think about what else could go wrong on either side of it. In this case, I have considered data flowing from stdout on the high privilege side of the boundary.
But what about stderr? You can see from the script that I am not explicitly logging anything sensitive in my code, but what about the event tap, or the enchant library? If something goes awry in a call to enchant::Dict::get will the last characters entered from the keyboard (or worse, a whole word) be sent across the trust boundary in a backtrace?
Part of application security (threat modeling, to be more specific) is brainstorming what could go wrong along a trust boundary, what the potential impact is, and what can be done about it.
In this situation, I am just trying out a new personal data experiment locally, so this script is probably OK. If a malicious user can execute code locally to read the output of spellcheck.py, I am already in a lot of trouble. However, if I wind up doing more with the output from the script or rolling it into a proper app, these questions and more would need to be asked and answered.
There are differing philosophies out there, but this is one place where open sourcing can help – getting the code around trust boundaries out there allows other users to ask questions, contribute patches, generally have an idea of what they are getting themselves into when the use your app. There are no magic bullets here (see also: Kerchoff’s Principle).
Stay tuned for more information on this crazy spell-checking experiment. As usual if you have questions, feedback, or want to chat about any of these topics, feel free to drop me a line or start a conversation below. Thanks for reading!
Footnote
Spelling and syntax corrections are always welcome here – I didn’t use a spellchecker when writing this blog post :). Also, for those of you playing along, git-shadow reports for this script:
Total time coding (days, H:M:S): 1:09:56
Total commits: 111
This means that I spent about 1 hour and 10 minutes coding up this script, with 111 edits (“shadow commits”) across the codebase.