A paper towards using Quantified Self data to become a better developer
Why
After reading Nicholas Carr’s The Shallows on the way back from a long, exhausting business trip I became interested in the notion of quantifying the benefits of unplugging. It seems like an appropriate idea given exponentially-increasing capability of the human-internet machine to collect data on users, and the very tangible (although boring) benefits of the conventional wisdom of spending the majority of your time doing things in your immediate, physical surroundings (you don’t have to take my word on this – this is a really old idea that is being re-discovered).
I work in software engineering so applying this idea to software development is appealing to me. To paraphrase Gerald Weinberg,
It's always a people problem.
Anyway, while I was sitting in my basement coding a toy app with a modified cheapo off-the-shelf EEG strapped to my head, Andrew Begel et. al. were publishing a paper (Using Psycho-Physiological Measures to Assess Task Difficulty in Software Development) that represents an actual methodical study of the subject.
This post is a dump of my rough notes on the paper.
The paper: “Using Psycho-Physiological Measures to Assess Task Difficulty in Software Development”
My take
Begel, et al. invited a cadre of professional software engineers to a lab for the study, using the usual licenses of MS software as an incentive. While they had some minor success in predicting the difficulty of tasks, there is much to be gleaned from their approach. As developers and teams learn to harvest their own big data for self-improvement the quality of this sort of prediction should increase.
Results
- Predict “easy” v. “difficult” code comprehension task
- For a previously-unknown developer,
- 64.99% precision, 64.58% recall
- For a previously-measured developer
- 84.38% precision, 69.79% recall
- For a previously-unknown developer,
- Using EDA, EEG, and eye-tracking
- “Using just the eye-tracking data resulted in even greater predictive power”
Precision v. Recall Review:
-
Precision example: for a developer wearing the sensor-system, the system predicted that X of the difficult tasks he was about to complete were difficult. Y is the total number of tasks that the system predicted as difficult (including false positives that the system incorrectly thought were difficult). Precision = X/Y.
-
Recall example: for a developer wearing the sensor-system, the system predicted that X of the difficult tasks he was about to complete were difficult. Y is the total number of difficult tasks that the developer was exposed to (including the false negatives that the system missed). Precision = X/Y.
… So you need both to make an effective bug prediction system. 85% and 70% for a previously-measured developer
Interesting related work
- Parnin found a correlation between utterances and a developer editing code
To study the link between code reviews and defect detection, researched have also examined the time developers spend scanning code by summarizing [eye-tracking] fixation durations over specific areas of interest and counting the number of fixations. Thereby, they found that a longer scan time correlates significantly with a better defect detection.
Khan et al. have looked into another psycho-physiological aspect and its link to performance by investigating how the mood of developers affects debugging and programming.
- Using NASA Task Load Index (TLX) survey for assessing cognitive load
Notes
We found that combining subsets of sensors with particular time windows could improve classifier performance when predicting task difficulty [...]
On EEGs
[...] decided to use an off-the-shelf NeuroSky Mind-Band EEG Sensor [...]
[...] use a Matlab-based 60Hz notch filter to remove signal noise caused by overhead lights. To identify various mental states [11], we use Matlab's pwlech function [...] Since every person has a unique power spectrum distrubition, we compute the ration of each band with one another to compare the values between individuals. In addition, inspired by Kramer and Lee, we compute Beta/(Alpha+Theta), and Theta/(Alpha+Beta) as additional measures of task difficult.
-
Also used for eye blink detection
-
It appears that all of these features were used with their Naive Bayes classifier (Weka)
Good tables
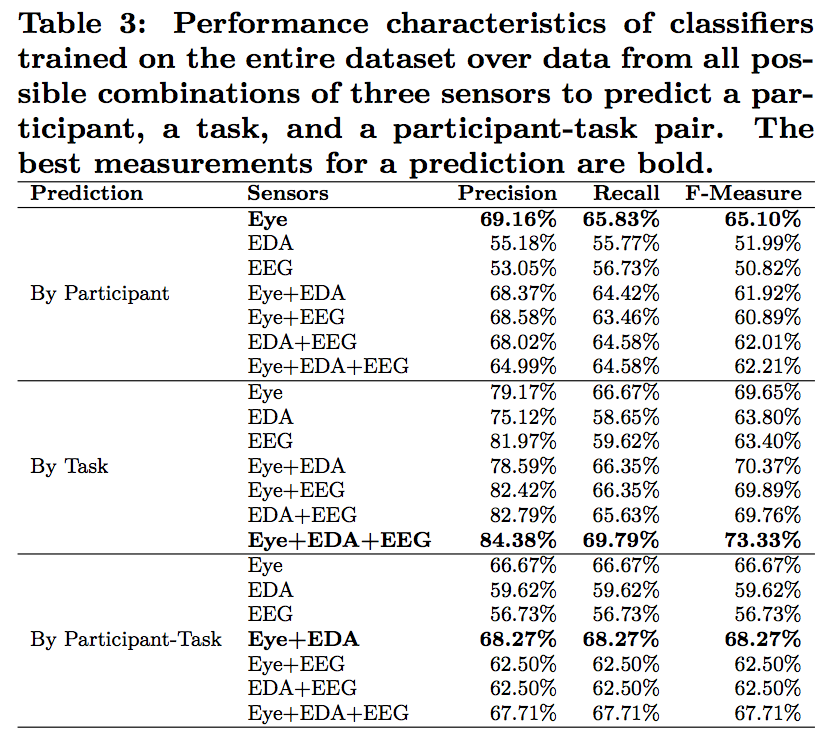
The by participant classifier would be the most useful in practice — trained on a small set of people doing program comprehension tasks, it could be applied to any new person doing new tasks and still accurately assess task difficulty. Next, in utility, is the by-task classifier; when trained on people doing a set of tasks, it would work well when applied to one of those people doing any new task. Finally, the by-participant-task pair classifier shows the proof-of-concept — trained on a set of people doing programming tasks, it can predict the diffi- culty of the task as perceived by one of those people doing a task that the rest already did.
The results aren’t a home run, but the approach is quite promising. As people learn to harvest their own big data the quality of prediction should increase.
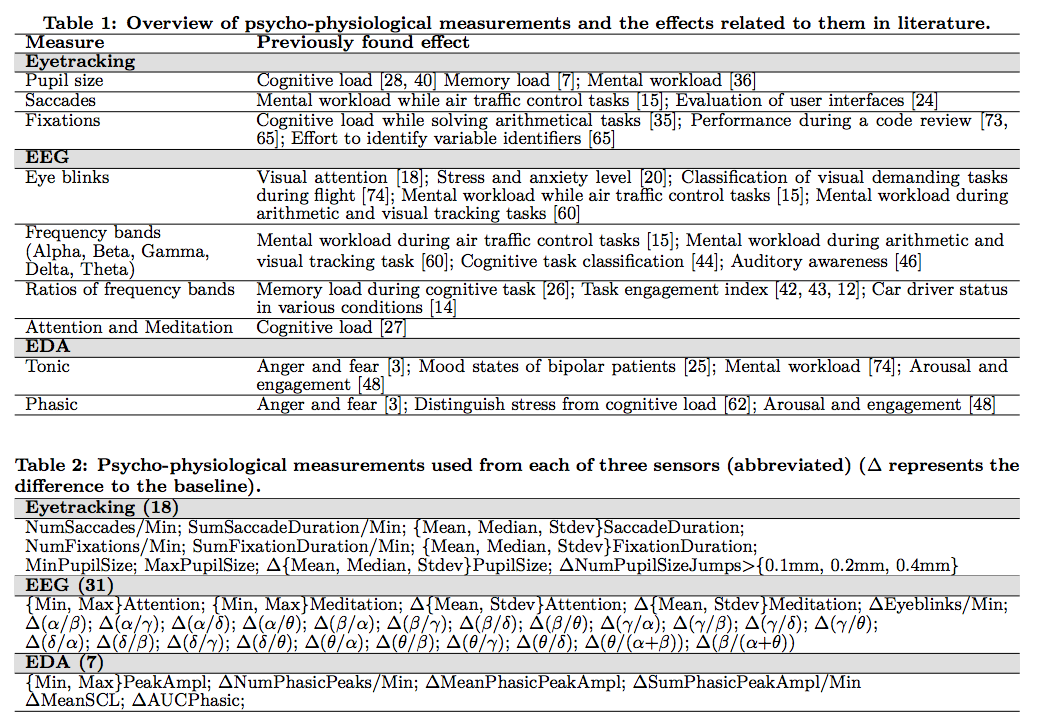
Just look at all that data.
