Code Ownership for git
TL;DR
Released toy git command git-ownership to ascertain ownership of code in git repositories.
Using Code Ownership to Predict Bugs
In 2011 Christian Bird, Nachiappan Nagappan, Brendan Murphy, Harald Gall, and Premkumar Devanbu published a paper titled “Don’t Touch My Code! Examining the Effects of Ownership on Software Quality”. The work appears as a reference in several highly-connected papers on the subject of predicting bugs and mining software repositories.
There are many qualifications here, but the concept advertised in this paper is interesting: there may be a high correlation between several code ownership metrics and both pre- and post-release faults. Data that the authors gathered, analyzed, and presented from the development and release of Windows Vista (and Windows 7 to a lesser extent) seems to support this idea.
Below is a figure from the paper that demonstrates the idea of ownership between two DLLs: A.dll is considered to have higher ownership, and B.dll is considered to have lower ownership.
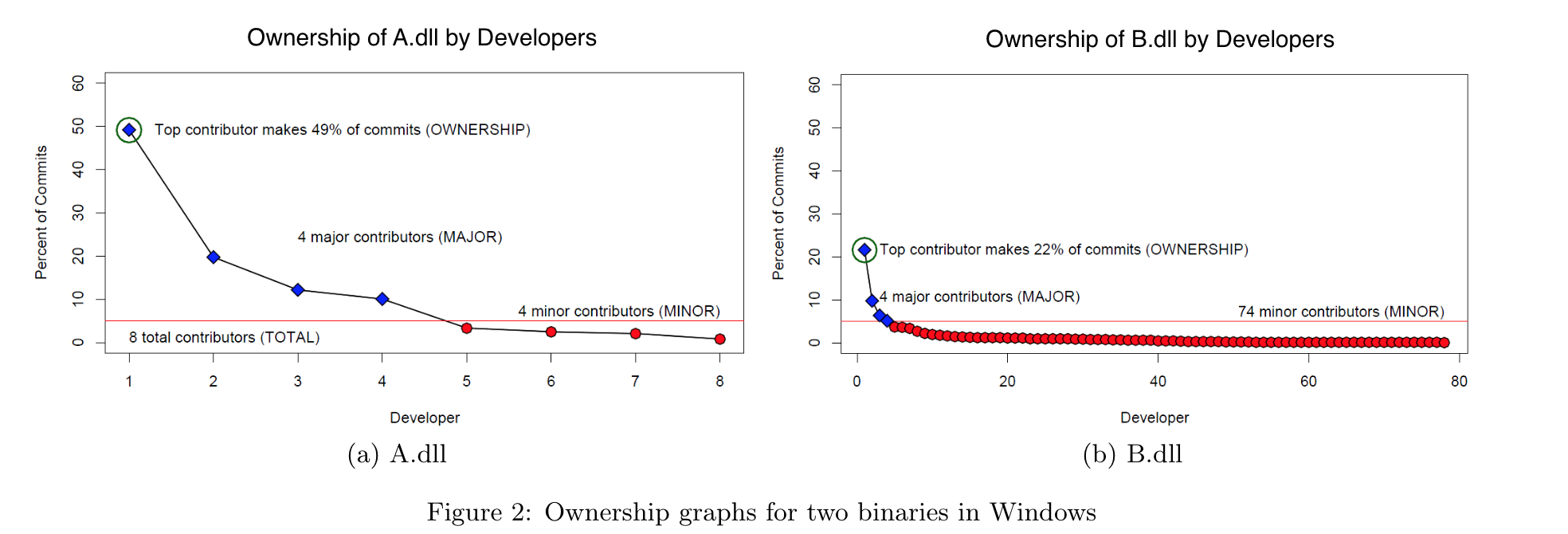
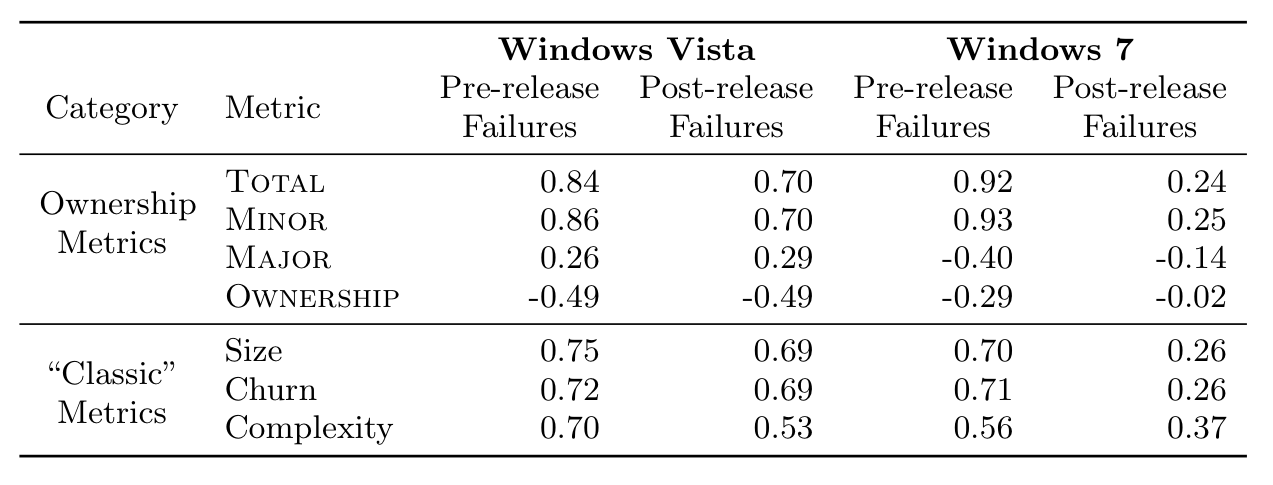
There is a solid discussion of statistical qualification in the paper, but the idea can be summarized by this table, which shows the bivarate spearman correlation of ownership and code metrics for the data set.
Between years as a software engineer, working full-time as a security engineer, and continually tinkering with code I was interested enough to script git-ownership over the weekend and try this idea out on some real-world projects.
Without a manpage, help, or verbose output (sorry), we have to cover some definitions from the paper to understand what the tool does.
{kind=link}
Definitions required to grok the tool output
Component: A unit of development that has some core functionality; defects must be traceable back to a component and changes must be traceable to component - for Windows, binaries (executables, DLLs, etc.) were considered components
[Proportion of] Ownership: Ratio of number of number of commits a developer has made to a component proportional to the total number of commits for a component. Some important caveats on this:
We use number of changes because each change represents an “exposure” of the developer to the code and because the previous measure of experience used by Mockus and Weiss also used the number of changes. However, prior literature [14] has shown high correlation (above 0.9) between number of changes and number of lines contributed and we have found similar results in Windows, indicating that our results would not change significantly.
and
Branching operations (e.g. branching and merging) were not counted as changes.
Major Contributor: A developer who has made changes to a component but whose ownership is greater than or equal to 5%
Minor Contributor: A developer who has made changes to a component but whose ownership is less than 5%
The tool: git-ownership
git-ownership provides a means to calculate ownrshp (the Proportion of Ownership above), majors (the number of Major Contributors above) and minors (the number of Minor Contributors above) for git objects in a manner similar to other drop-in git commands, like Gary Bernhardt’s git-churn. Here are some examples of how it works:
1. Put the script on your path
$ curl https://raw.githubusercontent.com/jfoote/git-ownership/master/git-ownership > /usr/local/bin/git-ownership
$ chmod +x /usr/local/bin/git-ownership
2. cd into an interesting git repository
$ git clone https://github.com/joyent/node
$ cd node
3. Try it out
Note: While I had some immediate success correlating metrics from this tool with bugs, the examples below are completely benign. They are meant to demonstrate usage only.
Running the git ownership without any additional arguments will print ownrshp, major, and minor for all files in the repo along with the same stats for the whole repo.
$ git ownership
[..snip..]
19 4 35 lib/repl.js
14 4 43 doc/api/http.markdown
20 4 49 lib/fs.js
31 4 52 src/node_crypto.cc
42 4 56 src/node.js
37 3 57 lib/http.js
43 4 60 lib/net.js
42 5 67 src/node.cc
--------
ownrshp major minor file
32 5 656 (all)
Results are sorted by minor as this had the highest correlation with defects in the paper. Also note that the function used to produce these stats is not additive: ownership for the whole repository is not the sum of ownership for each file
While the authors call out repeatedly that this metric may not be applicable in other development processes, other definitions of component, and so on, the results above seem to that there are several files that have low “ownership” and might be worthwhile to spend on time analyzing for bugs. git-ownership is just a toy for now, however, so I haven’t done any rigorous analysis.
To demonstrate a quick hack, suppose that node.js components are contained in folders. git-ownership passes additional parameters on to git-log, so it can be used to slice the application this way as well.
$ find . -type d -depth 1 -exec git ownership {} \; -print | grep -A1 "(all)"
38 3 19 (all)
./benchmark
[..snip..]
--
39 5 45 (all)
./deps
--
26 3 304 (all)
./doc
--
25 4 345 (all)
./lib
--
35 5 200 (all)
./src
--
35 3 315 (all)
./test
--
40 4 39 (all)
./tools
Happy coding.